Making LLaMA SEE and Draw with SEED Tokenizer
For any inquiries, please email seed-x@googlegroups.com

Updates
[16 Jan 2024] SEED-LLaMA has been accepted by ICLR 2024.
[20 Oct 2023] We have released our checkpoints on Huggingface, and an online Gradio Demo. Welcome to check them out.
[7 Oct 2023] Check out our trailer (in English) on X (Twitter).
[2 Oct 2023] Our technical report has been released on arXiv. The checkpoints, code, and online demo will be available in late October. Stay tuned!
[29 Sep 2023] Check out our trailer (in Chinese) on WeChat (scan the QR code).
Abstract
We upgraded the SEED visual tokenizer (find the initial version here) and proposed SEED-LLaMA-8B/14B foundation models. The SEED-2 tokenizer can better preserve the rich visual semantics and reconstruct more realistic images. SEED-LLaMA is produced by large-scale pre-training and instruction tuning, demonstrating impressive performance on a broad range of multimodal comprehension and generation tasks. More importantly, SEED-LLaMA has exhibited compositional emergent abilities such as multi-turn in-context multimodal generation, acting like your AI assistant.
SEED-2 Tokenizer
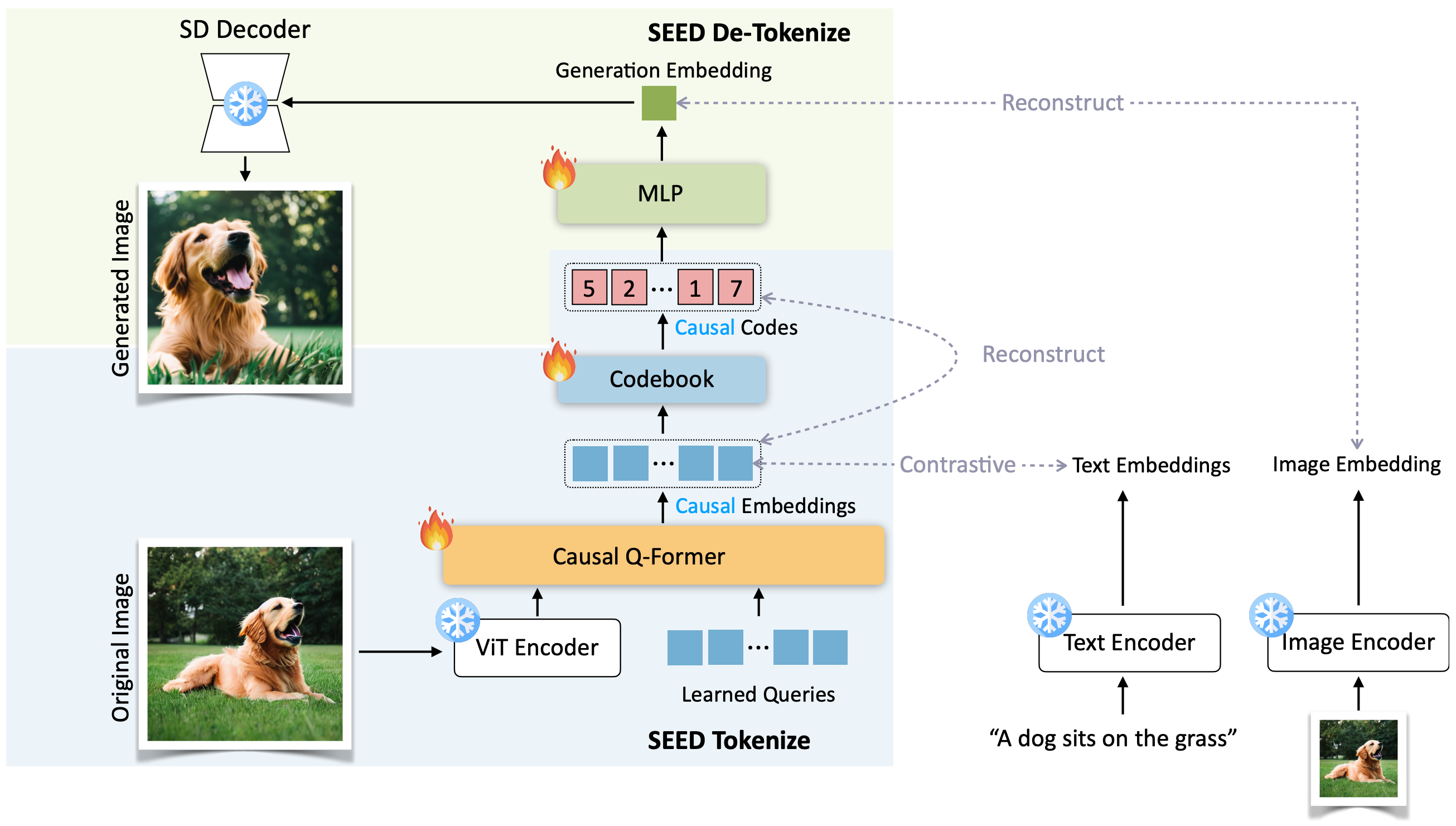
Core differences from SEED-1:
- In SEED tokenizer v2, the generation embedding is aligned with the image embedding (1 token) of unCLIP SD, and can be decoded to realistic images with the unCLIP-SD-UNet.
- In SEED tokenizer v1, we train a visual tokenizer through aligning the generation embeddings with the text embeddings (77 tokens) of SD, and the generation embeddings can be decoded to images with the SD-UNet.
The below figure shows the visual comparison of the reconstructed images between SEED tokenizer v2 (the third row) and SEED tokenizer v1 (the second row). We can observe that the images reconstructed by SEED tokenizer v2 can better preserve the visual information of the original images, since the semantic representations of texts can not fully preserve the rich visual information of images.

(i.e., original image (a) → SEED tokenize → causal visual codes → SEED de-tokenize → reconstructed image).
SEED-LLaMA
We develop SEED-LLaMA-8B and SEED-LLaMA-14B, based on Vicuna-7B and LLaMA2-Chat-13B, respectively:
- Multimodal pre-training: SEED-LLaMA-8B and SEED-LLaMA-14B were pre-trained with 64 A100-40G GPUs by 144 and 216 hours, respectively.
- Multimodal instruction tuning: The pre-trained SEED-LLaMA-8B and SEED-LLaMA-14B were further tuned with 32 A100-80G GPUs by 16 and 27 hours, respectively.
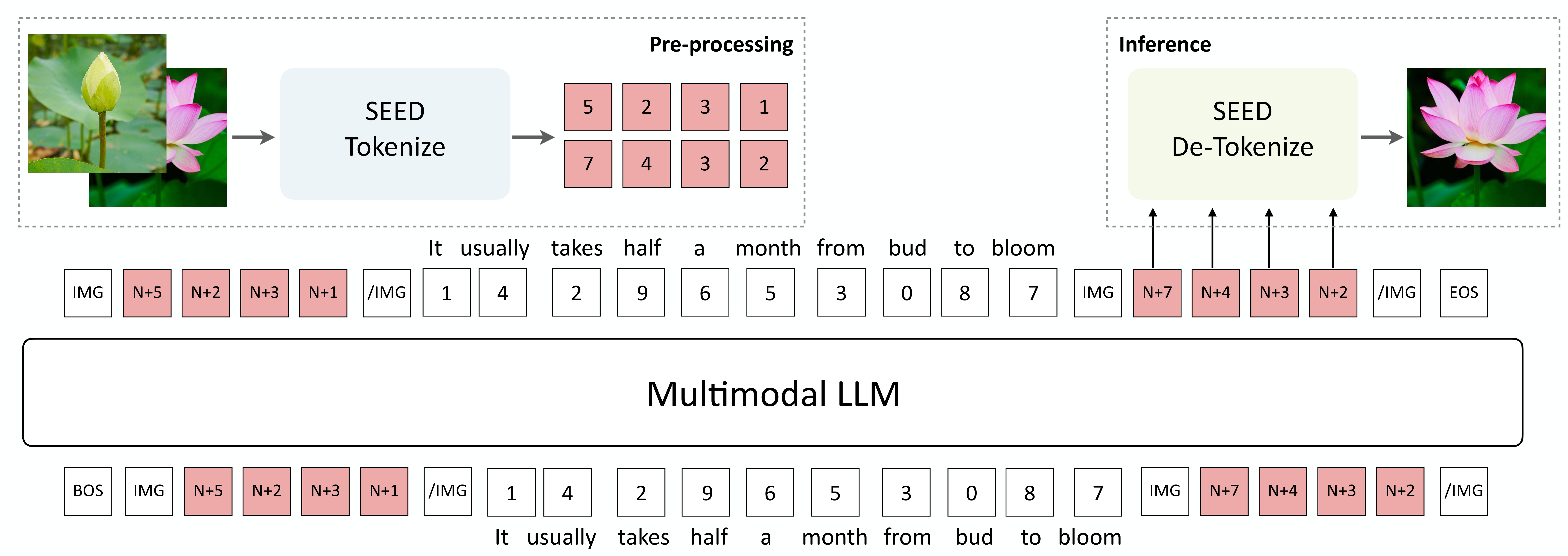
Taking the pre-training stage as an example, SEED-LLaMA adopts a unified next-"word"-prediction training objective on interleaved visual and textual data (as illustrated above), which are constructed based on image/video-text pairs and image-text interleaved documents (including COCO Caption, CC3M, Unsplash, LAION-COCO, MMC4, OBELISC, and WebVid).


Please refer to our technical report for more training details and results.
Citation
@article{ge2023making,
title={Making LLaMA SEE and Draw with SEED Tokenizer},
author={Ge, Yuying and Zhao, Sijie and Zeng, Ziyun and Ge, Yixiao and Li, Chen and Wang, Xintao and Shan, Ying},
journal={arXiv preprint arXiv:2310.01218},
year={2023}
}
Get to know more about our Project SEED.
Acknowledgements
The website template was borrowed from Open X-Embodiment.