 ViT-Lens
Towards Omni-modal Representations
ViT-Lens
Towards Omni-modal Representations

Design Pattern and Results
(I) Understanding across modalities
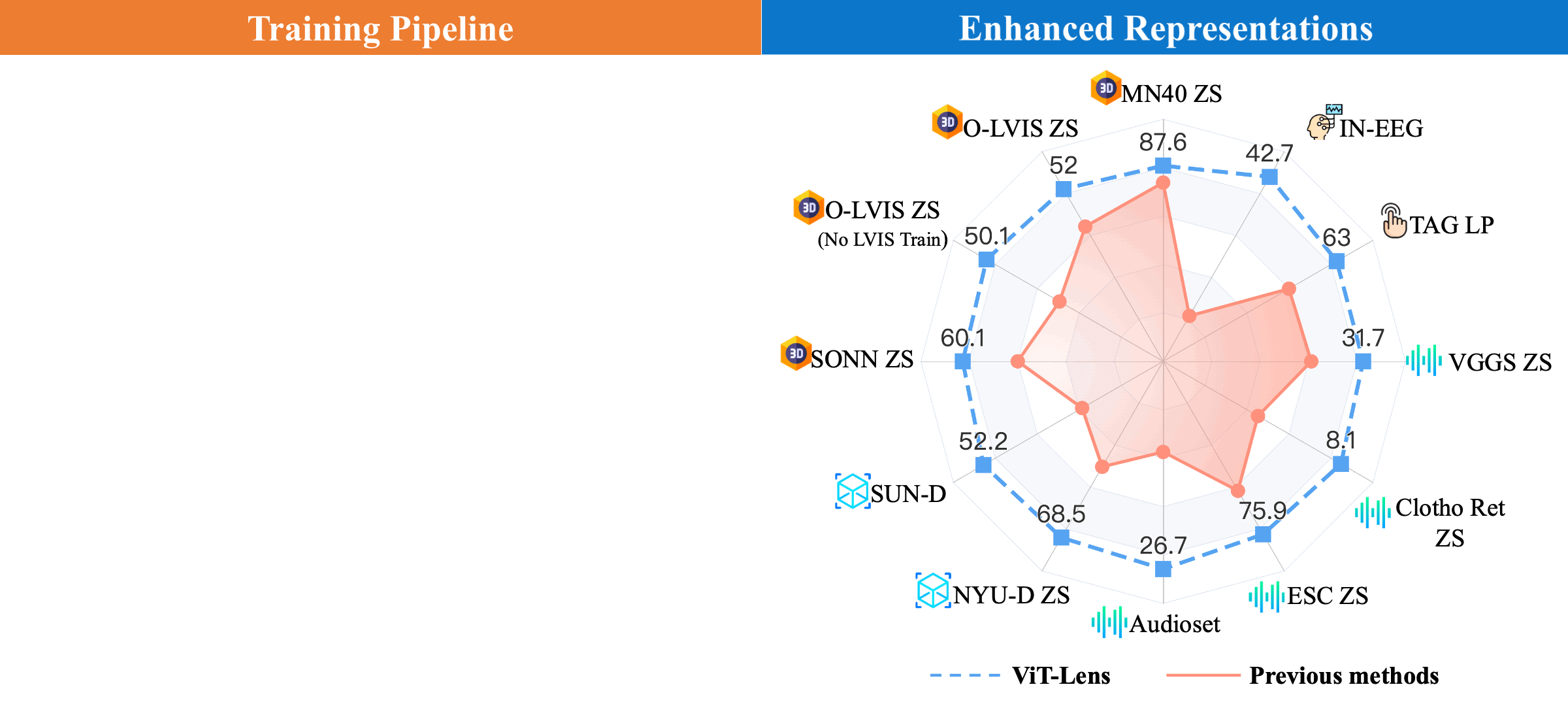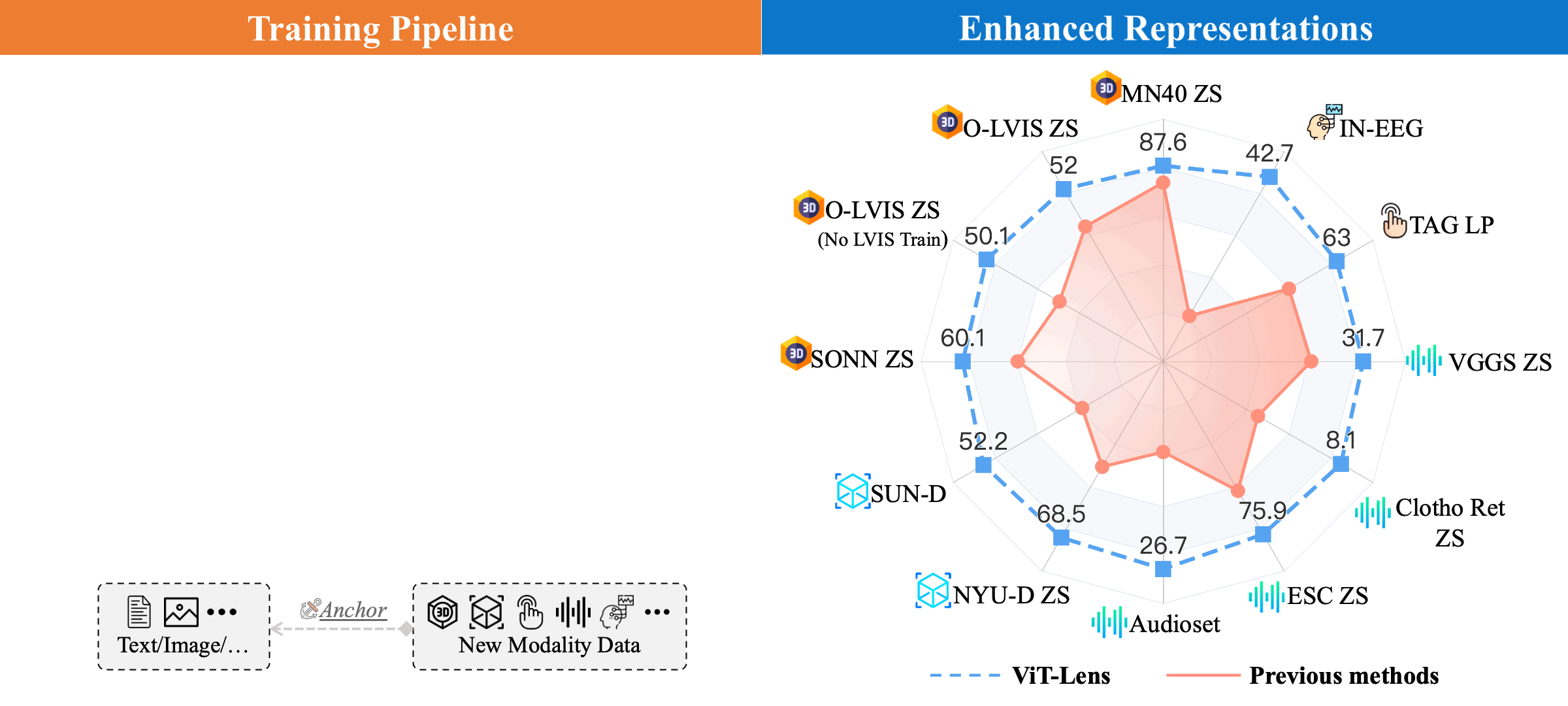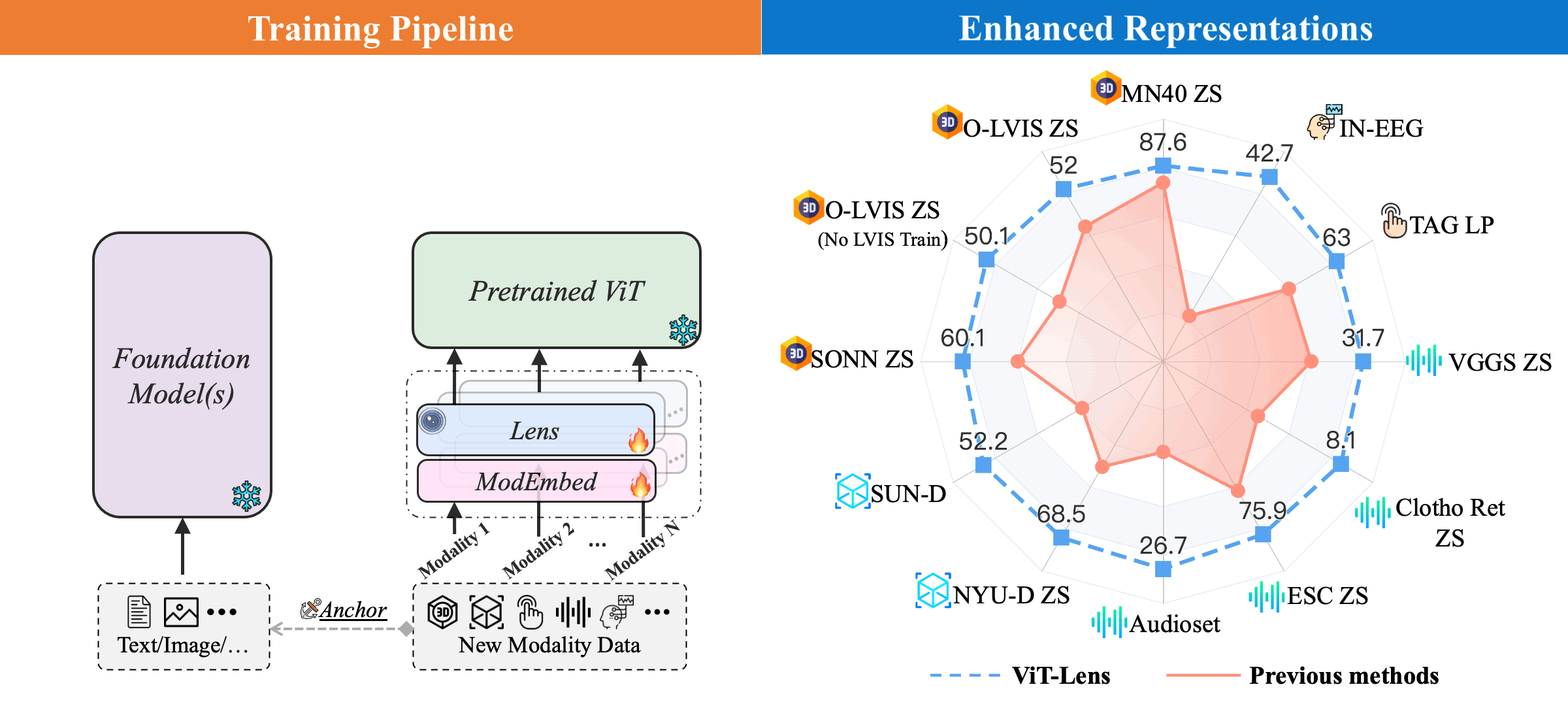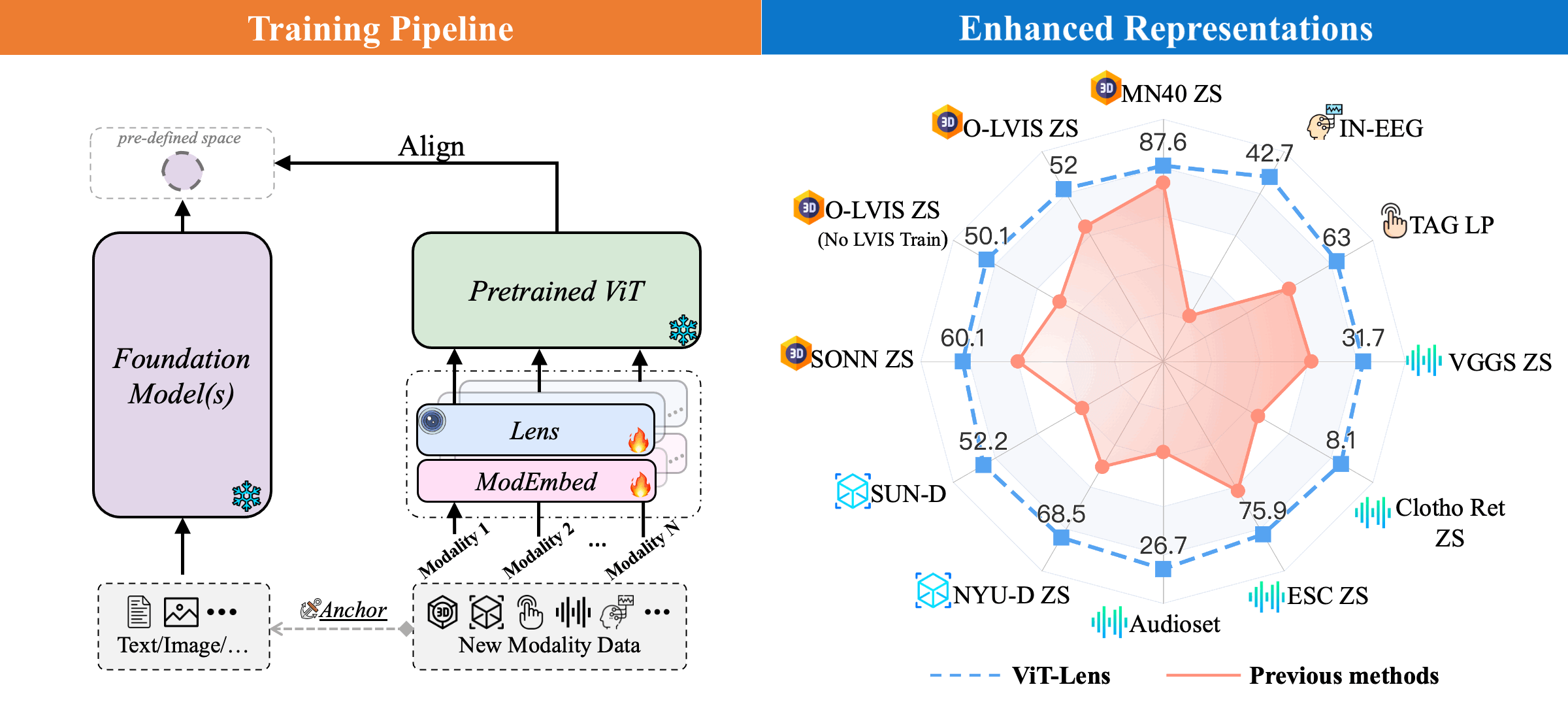
(Left) Training Pipeline: ViT-Lens extends the capabilities of a pre-trained ViT to diverse modalities. For each novel modality, it firstly employs a Modality Embedding (ModEmbed) and a Lens to learn mapping modality-specific data into an intermediate embedding space. It subsequently employs a set of pre-trained ViT layers to encode the feature. Finally, the output feature is aligned with the feature extracted from the anchor data (image, text, etc.) of the new modality using an off-the-shelf foundation model.
(Right) Performance on Understanding Tasks: ViT-Lens consistently enhances the performance and outperforms previous methods on understanding tasks, such as classification, zero-shot classification (ZS) and linear probing (LP), across 3D point cloud, depth, audio, tactile, and EEG modalities.
(II) ViT-Lens integration to MLLMs
Illustration of training-free ViT-Lens integration: By incorporating the ViT from MLLM as part of the modality encoder and as the foundation model in ViT-Lens training, the yielded modality Lenses can be seamlessly integrated into the MLLMs (e.g., InstructBLIP and SEED) for plug-and-play application.



(3D to Image) Generate an image based on what you see.


(3D to Image) Generate an image based on what you see.


(3D to Image) Generate an image based on what you see.


(3D to Image) Generate an image based on what you see.

(Audio to Image) Generate an image based on what you perceive.

(Audio to Image) Generate an image based on what you perceive.

(Audio to Image) Generate an image based on what you perceive.

(Audio to Image) Generate an image based on what you perceive.

(Audio to Image) Generate an image based on what you perceive.

(Audio to Image) Generate an image based on what you perceive.


(EEG to Image) Generate an image based on what you see.


(EEG to Image) Generate an image based on what you see.


(Tactile to Image) Generate an image based on what you see.


(Tactile to Image) Generate an image based on what you see.


(EEG to Image) Generate an image based on what you see.


(Tactile to Image) Generate an image based on what you see.


(Compound 3D to Image) Add Christmas atmosphere. Generate an image.


(Compound 3D to Image) Add Halloween atmosphere. Generate an image.


(Compound 3D to Image) Add a cat. Generate an image.


(Compound 3D to Image) Add beach in the background. Generate an image.


(Mixed Modalities to Image) Combine these two visual concepts. Generate an image.


(Mixed Modalities to Image) Combine these two visual concepts. Generate an image.
Notes
- Citation: If you are using the ViT-Lens code and models in your research or are inspired by our work, please cite.
- License: Our code, models and data are distributed under Apache 2.0 License.
- Others: Check out other projects of our team.
Acknowledgements
The website template was borrowed from Open X-Embodiment.